After reading an article about implementing a poor’s man datalake using Polars and Delta I thought I needed to give it a go. Coming from Spark, I was familiar with how to work with Delta, and a pattern I used a lot for incremental pipelines was structured streaming to stream new rows. This is a very useful pattern, that you can trigger to stream all new changes and stop it, but the same is not that easy to achieve with Polars.
This is where Change Data Feed comes into place, CDF lets you read all the changes that has happened between two versions or timestamps in Delta and will let you know when the change happened and what type of change is it.
With this we can dust off the old Watermark pipeline pattern to change a pretty effective incremental pipeline without extra overhead of managing yourselves the metadata of what and when the changing are happening.
The basics
Delta already stores the data as a log of changes. If you inspect the history or the metadata of a delta table, you can see information about the operations that have happened in the table and you can read the delta at a point in time or version. Delta then recreates the version by picking the files and applying all the operations in the log to the last available snapshot.
CDF is an extension of this, with it enabled, delta not only stores the metadata of the operation, but the individual changes in an alternative location, so you can query it.

Creating table and enabling CDF
Lets get working, CDF needs to be enabled as a feature on the delta table and it was not available on old version of delta lake, so we need to update the
We have 2 options to enable it to an existing table:
from deltalake import DeltaTable, TableFeatures
dt = DeltaTable(t)
# Option 1
dt.alter.set_table_properties({
"delta.minWriterVersion": "7",
"delta.minReaderVersion": "3",
"delta.enableChangeDataFeed": "true"
})
# Option 2
dt.alter.add_feature(TableFeatures.ChangeDataFeed, allow_protocol_versions_increase=True)
Or to create the table directly with CDF enabled:
df.write_delta(
table_path,
delta_write_options={
"configuration": {
"delta.minWriterVersion": "7",
"delta.minReaderVersion": "3",
"delta.enableChangeDataFeed": "true"
}
}
)
After this you can run any the following queries to make sure that CDF is enabled correctly:
dt.metadata().configuration
# Output
{'delta.minReaderVersion': '3',
'delta.enableChangeDataFeed': 'true',
'delta.minWriterVersion': '7'}
You can also find it if you check the protocol of the delta table:
dt.protocol()
# Output
ProtocolVersions(min_reader_version=3, min_writer_version=7, writer_features=['changeDataFeed'], reader_features=None)
It is important to note that if you enable CDF after a table is created, you won’t be able to read the changes from it, only from future versions after enabling, that is, load_cdf(0) will raise and error, at least as the time of writing this article
Structure of CDF
Now that we have enabled CDF, after making updates there will be a new folder beside _delta_log, _change_data, that will store the changes.

If you check the delta logs, there is new section cdc, that stores the path to the _change_data, which in combination with the metadata of the update allows the delta reader to generate the changes.
This is an example of the delta log

And this is for the _change_data/ files
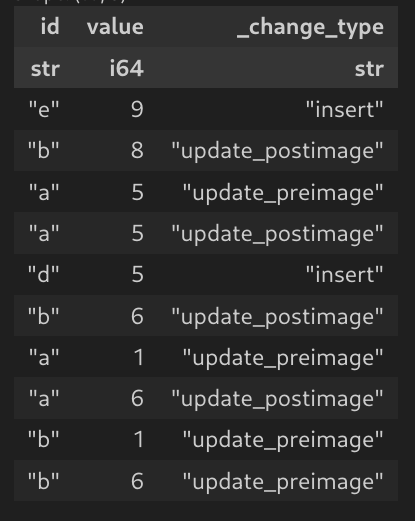
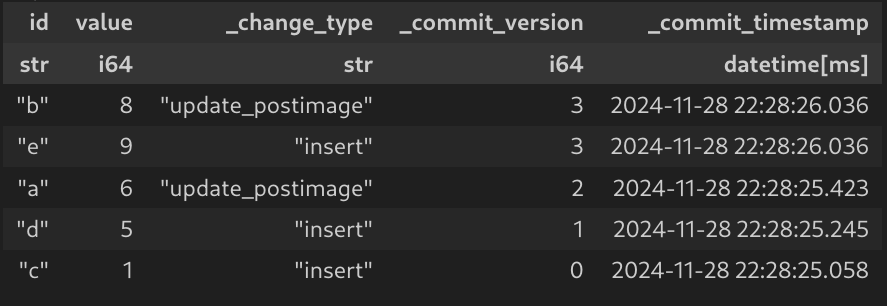
Now putting it all together, we can leverage the delta lake reader to give us the reconstructed changes. When we run the following code:
dt = DeltaTable(path)
dttable = dt.load_cdf(
starting_version=0
).read_all()
pt = pl.from_arrow(dttable)
This is what you would get:
Watermark pipeline
Now that we have all the technical details of how to read the changes, the watermark pipeline is a way of leveraging it to incrementally read the source table and apply the changes only the rows that have been changed sin last update.
Traditional watermark pipeline
The traditional pattern when reading tables from a database that have a modified_time columns is to have a:
- low_watermark: the watermark of the previews load
- high_watermark: the maximum watermark that is available on the source
You then select the data between those watermarks:
SELECT *
FROM source
WHERE low_watermark < modified_time AND modified_time <= high_watermark
And after applying any transformation need and updating the target table, you store the high_watermark as the new watermark.
Watermark pipeline using delta

Now, using this concept, the steps would be:
- Read the previous watermark
- Use
load_cdf(low_watermark + 1)to read the next changes - Apply transformations and write incremental changes
- Update watermark
As of what we are storing in the watermark table, the minimum would be:
- The target table name or id (for example the path)
- The watermark of the source table, can be either the version or timestamp But this can be extended to have more meta information of the incremental pipeline
Putting it all together (Example of pipeline)
This is just an incomplete example to show more or less how all fits together, to get more details plus some more auxiliary functions there is notebook in github that you can see.
import polars as pl
from deltalake import DeltaTable
from typing import List
def read_watermark(table_path, watermark_table):
watermark_df = pl.read_delta(watermark_table).filter(pl.col("table_path") == table_path)
watermark = watermark_df.select("watermark_version").item() if watermark_df.select(pl.len()).item() != 0 else None
return watermark
def delta_changes_from_version(
path: str,
key_columns: List[str],
starting_version: int = 0,
ending_version: int = None,
drop_cdf_columns: bool = True
) -> pl.DataFrame:
dt = DeltaTable(path)
dttable = dt.load_cdf(
starting_version=starting_version,
ending_version=ending_version,
).read_all()
pt = pl.from_arrow(dttable)
if starting_version:
pt = pt.filter(pl.col("_commit_version") > starting_version)
# Get only the latest state for each row
changed_rows = (
pt
.with_columns(rn=pl.col("_commit_version").rank("dense", descending=True).over(key_columns))
.filter(pl.col("rn") == 1)
.filter(pl.col("_change_type").is_in(["insert", "update_postimage"]))
.drop("rn")
)
if drop_cdf_columns:
changed_rows = changed_rows.drop("_change_type", "_commit_version", "_commit_timestamp")
return changed_rows
# Auxiliary function that merges data or creates it if the delta does not exist
def try_merge_delta(df, table_path, predicate, content_predicate=None):
...
# Parameters
source_table_path = "_output/test/incremental"
target_table_path = "_output/target"
watermark_table = "_output/watermark"
merge_columnns = ["id"]
# Create empty watermark table
empty_watermark = pl.DataFrame([], schema= pl.Schema([
('table_path', pl.String),
('merge_columns', pl.List(pl.String)),
('watermark_version', pl.Int64),
('watermark_timestamp', pl.Datetime(time_unit='us', time_zone=None))]
))
DeltaTable.create(watermark_table, schema=empty_watermark.to_arrow().schema, mode="overwrite")
# Now on each increamental run
#
# Read watermark
low_watermark = read_watermark(target_table_path)
rows = delta_changes_from_version(
source_table_path,
starting_version=low_watermark or 0,
key_columns=merge_columnns,
drop_cdf_columns=False
)
new_watermark_version = rows.select(pl.max("_commit_version")).item()
new_watermark_ts = (
rows.filter(pl.col("_commit_version") == new_watermark_version).select(pl.max("_commit_timestamp")).item()
if new_watermark_version else None
)
# Do something with rows to write to the next layer
# ...
# Update watermark
if new_watermark_ts is not None:
watermark_update = pl.DataFrame(
data=[[source_table_path, merge_columnns, new_watermark_version, new_watermark_ts]],
schema=["table_path", "merge_columns", "watermark_version", "watermark_timestamp"],
orient="row"
)
try_merge_delta(watermark_update, watermark_table, "source.table_path == target.table_path")
data-examples/incremental_pipeline/incremental_pipeline.ipynb at main · pblocz/data-examples
Closing notes
The examples and notebooks assumes that there is only a single source, but if you had multiple sources, you can store them in table as multiple rows. As well as this, the example assumes that there is only going to be inserts and updates, but if deletes are an option, adapting the code to consider them is only quite straightforward.
Also, if you are doing aggregations or joins, you might need more information than only the available on the watermark, so an extension of this pipeline might be to join back to the source table to the whole window of data that you need. For example, if we are doing an aggregation by day, and our source table has information by hours, we can take the updated rows and join back to get the full day in case the updates we got were partial updates.
With all this, CDF makes is quite seamless to build incremental pipelines. You could build it yourselves by having to manage the timestamp column or version on the update. It is not much overhead and a known pattern, but with this, you can just forget about all that metadata and focus on the data itself.